

SQR-080
Health-check notebooks organisation and mobu roadmap#
Abstract
An organising structure for notebooks driven by mobu (and/or available for ad-hoc use) for the purposes of conducting system health checks.
Abstract#
An organising structure and improvement roadmap for notebooks driven by mobu (and/or available for ad-hoc use) for the purposes of conducting system health checks.
Background#
SQuaRE’s stable of services includes mobu, a harness that continuously uses flocks of bot users to perform realistic workloads on our systems, particularly in the Rubin Science Platform. While mobu is agnostic about the kind of payload it executes, in practice the most widely used mobu content is notebooks that can be executed in the Rubin Science Platform. Not only does this kind of payload provide deep integration testing of multiple services (and data holdings) under realistic usage conditions, but it also makes it easy for us to leverage content written for other purposes (eg science tutorials) for testing and monitoring.
At the time this technote was first written (July 2023) mobu runs payload from two repos:
system-test
This is the original testing repo. It contains a mix of simple tutorials, service demonstrations and ad-hoc troubleshooting notebooks for historical reasons. All run fast and use minimal amount of data, though they do make assumptions about what data collections are available. Contributions are generally from service developers and are curated by the Rubin Data Services teams.
tutorial-notebooks
These are notebooks containing substantive science usecases. This repo contains complete tutorials that need specific data collections and types and can be sensitive to specific versions of the Rubin Science Pipelines. Some of these notebooks take non-trivial amounts of time to run to completion, and could involve a non-transient load on underlying services. Contributions are primarily from scientists and are curated by the Rubin Community Science Team.
For reasons that relate to the capabilities of mobu’s antecedent prototype, both repos reflect certain operational decisions such as:
They have a “prod” branch as the production branch with “main” as the development branch.
A checkout of the prod branch is automatically included (and updated) in each user’s home space on data.lsst.cloud
These checkouts are write-protected to avoid users ending with a dirty copy.
Goal#
The goal of this technote is to outline a plan to address operational frictions involving primarily the system-test repo and identify improvements that can be made to support the growing number and purposes of the notebooks run by mobu in the various Rubin Science Platform deployments.
Issues and solutions#
Notebook payload repos#
Before: Notebooks are in system-test and tutorial-notebooks as described above.
After: Notebooks to be in three repos:
tutorial-notebooks (no change)
system-test
curation-check
Discussion:
With the advent of the tutorial-notebooks, we have a large suite of well-curated full-workflow notebooks to emulate realistic user workflows, and therefore we no longer need to use system-test notebooks for this purpose. At the same time, we have a need for service checkout and monitoring in a large number of deployments, many of which do not have access to large facility datasets (such as the hardware teststands). So system-test should focus on
single-service (to whatever degree practical) checkout and monitoring notebooks
ad-hoc troubleshooting notebooks (not run under mobu)
In addition, we have identified a need for mobu-run notebooks that perform specific data checks, in some cases across deployments (for example: does the summit EFD and the USDF EFD agree on the number of measurements for a given topic during a particular time period). Given the strong semantic awareness of these checks and the need to compare data holdings across cluster, these will live in a separate repo (curation-check) and will contain payloads in separate directories that either (a) run on a specific deployment or (b) compare data in different data facilities. For the latter, given the fact that some of these comparisons will involve data holdings behind a VPN (such as the summit EFD, summit Butler etc), these should run from within a VPN deployment. Pressure of resources at the summit would suggest the best home for them would be to run under the base cluster’s mobu.
Service-specific checks#
Before: Mobu can be configured to run all notebooks in a given directory and branch, but beyond that all notebook payloads in that directory/branch must work.
After: By leveraging a naming convention that matches the application name in phalanx, mobu uses the ArgoCD UI or the environment manifest to only run notebooks corresponding to deployed services.
Discussion:
We want a more fine-grained way of running only notebooks that are expected to complete successfully. However an opt-in approach of creating manifests of specific notebooks in a repo (or a proxy of the same result, such as having mobu run off different branches in different environments) is a maintenance headache. If instead we adopt a naming convention for notebooks that match the ArgoCD application name, mobu can be modified to run all notebooks from participating services. For example, if at the La Serena base deployment nublado is set to true in the environment yaml and tap is set to false and there were notebooks in system-test named
nublado_login.ipynb
nublado_dask_cluster.ipynb
tap.ipynb
mobu would run the nublado notebooks but not attempt the tap one.
The advantage of this approach is that developers can check in new notebooks for services without necessitating mobu changes.
Outcome:
Mobu now finds the list of phalanx applications are enabled in a given phalanx environment from the ArgoCD configuration. Notebook metadata can be annotated with the name of a service to ensure the notebook is not run if the service is not expected to be available. See the relevant mobu documentation for how to do this.
Notebook caching (or not)#
Before: Notebook caches notebooks and needs to be restarted to pick up new notebooks.
After: Mobu payload Github repos have a webhook that pushes a command to mobu’s API to refresh a newly merged Notebook
Discussion:
We don’t want to continuously poll Github from mobu because it will slam the API when we use mobu for scale testing. We could manually invoke an API or refresh on a timer, but a notebook on-merge is more elegant.
We still need to re-read on mobu (re-)start; this will be the only way to pick up notebook changes in sites without in-bound internet (eg the summit). It is a feature for the summit mobu’s behavior to remain stable until manual intervention in any case.
Outcome:
A (per environment) mobu refresh Github App has eliminated the need to restart mobu when changing configured pay load repos.
See the relevant mobu documentation for how to do this.
Reliance on specific data holdings#
Before: System-test notebooks address specific data holdings
After: Notebooks perform a data discovery step and run on arbitrary holdings and/or opt out of data-holding specific checks.
Discussion:
From the beginning we have identified the need to have a small data-set that is available on all deployments to allow system-test notebooks to run everywhere. While there is merit to this idea, in practice finding the effort to curate such a careful minimal in size but maximal in utility dataset has been hard to find. With the advent of the tutorial-notebooks repo, the requirement for performing substantive computations and/or service load has been eliminated from system-test. With the proposed data curation notebooks, that require specific data holdings can live elsewhere. To the extent that this is practical, system-test service notebooks should be written with a data discovery or data check step to see what data is available (eg. in terms of available catalogs, tap_schema could be queried first to make sure unavailable catalogs are not being requested). However since we ultimately plan to implement a data discovery service which will expand what is possible here, there is no need to implement more than some basic notebook-level logic (such as “is there a butler repo here I can use, yes okay use that”) at the present time when easy to do so.
Branches#
Before: Mobu typically runs the prod branch of the notebooks (though this is configurable) with notebooks having to be cherry-picked from main to prod.
After: End this madness.
Discussion:
The need to maintain two different branches has been eliminated with mobu’s ability to easily be configured to run off different branches for cases where it is useful to have an “in-development” version deployed. Hence cherry-picking is just annoying with no particular benefit.
Outputs#
Before: Notebook contributors need to remember to clear outputs before checking in new versions of the notebooks.
After: Have this happen automatically (via pre-commit hook or similar), or at least raise a CI warning if there is output checked in.
Discussion:
Having the human remember to clear outputs before saving and checking in is error prone. Even if the notebook ends in clear_outputs(), it still implies it was run to the end before commit. Ideally something like https://github.com/srstevenson/nb-clean would be integrated in the development workflow.
This may also be of use to other notebook repo maintainers.
Outcome:
There is a pre-commit hook (and a Github action that runs the pre-commit hook) installed in system-test (and can be installed in other payload repos) that automatically clears outputs from notebooks before they are committed.
Write-Only (or not)#
Before: Notebooks are checked out write-only in nublado to avoid conflicts
After: Tutorial-notebooks continue to be write-only (this has saved a lot of support headaches) and automatically checked out for rapid onboarding, while system-test notebooks can be read-write to allow for easier guided troubleshooting but only checked out on demand
Discussion:
We have struggled with this trade-off before where we want to give users the best and latest turtorials but also not trash any work that they may have in progress. Earlier we experimented by trying to resolve any such conflicts but this turned out not be 100% reliable. The compromise for tutorial notebooks is to check them out read only in people’s containers and guide them to make their own copy or checkout if they wish to modify them.
For other notebook types this is less satisfactory, especially with notebooks whose purpose might include involving being modified, which are unlikely to be changed by the user, whose presence on a science user’s home space might be confusing or whose target is a more advanced user who can resolve their own conflicts. Since these notebooks are by definition nublado notebooks, it makes sense to provide a menu option in our Jupyterlab UI extension to check out a fresh set, including warning that any currently checked out set will be overwritten. This means a user will have easy access to these additional repos without cluttering out their home space or having to resolve conflicts.
Mobu bot users check notebooks directly from Github and hence will not be affected by this.
Outcome:
We have resolved this by the new tutorial pull mechanism that populates tutorial notebooks on request and abandons the git checkout model.
Directories#
Before: Mobu runs notebooks only at the root level of repos
After: Run all notebooks, but skip notebooks in a directory included in an exclusion list.
Discussion:
There are a number of ways one can designate which notebooks are to be run (or not). Reasons for opting for a directory exclusion list include:
If you do nothing everything will run (it’s a mobu payload repo - not running is the exception)
Right now people put not-for-running (in development, deliberate error condition) notebooks in a directory to keep it away from mobu but with increasing content the top level is getting crowded
An exclusion manifest at directory granularity is less hassle than per-notebook (less bookkeeping when renaming, etc)
Whether to run or not is self-serve for repo maintainers and does not involve phalanx PRs.
Outcome:
A configuration file in the payload repo can be used to (recursively) exclude sub-directories. See the relevant mobu documentation for how to do this.
Summit#
Before: Mobu does not run at the summit
After: There are system-test notebooks that probe basic “telescope” functionality (eg communication with DDS)
Discussion:
These had better be passive, we don’t want to move the telescope or anything…. We should check what if any protections there are for this, eg is there further authorisation required to perform certain tasks
Timing#
Before: We have no timing information related to whole-notebook runs or per-cell runs (mobu collects it and exposes it via its API but it’s not stored for easy access / monitoring)
After: Notebook and/or cell execution time can be curated and monitored in Sasquatch.
Discussion:
This has been controversial in discussion with the reasonable argument that notebook execution relies on too many factors and excursions from the norm are not determinative. The other side of the argument is that metrics would indicate the statistical as-is user experience for execution times and can provide at least coarse statistics (if not for alerting, at least for inspection).
Any metrics should arguably be dispatched to Sasquatch for self-evident dogfooding purposes.
Outcome:
This functionality has been provided by the new phalanx metrics system. See the figure below
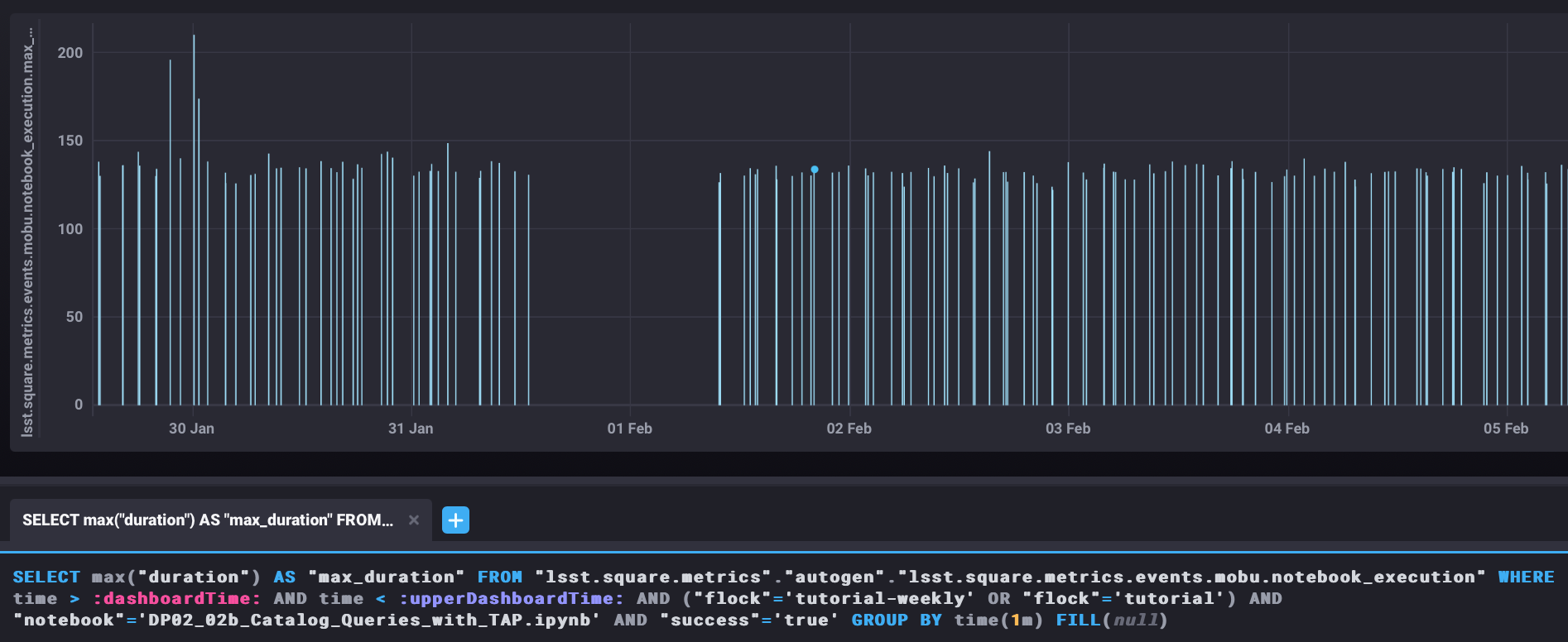
Fig. 1 Maximum (worst-case) duration for the (successful) execution of a tutorial notebook demonstrating catalog queries with Qserv.#
Recommended#
Before: There is no automated checking of future recommended candidates
After: A candidate recommended starts being mobu’ed (at least on data-int) as soon as it is identified
Discussion:
We already mobu the latest (most recent) weekly; the problem is that due to the time it takes to identify, test and deploy a new recommended image, the latest weekly is no longer the candidate recommended. Given the amount of human attention involved in bumping recommended, adding the candidate to a mobu configuration explicitly is no less expedient that engineering a specific pattern such as tagging the container.
Status:
[document process]
Mobu as CI#
Before: If someone breaks a notebook in a mobu payload repo we only find out after mobu runs on the merged
After: Mobu is registered as a CI hook and notebooks (eg tutorials) have to run green before merge
Discussion:
Humans are doing right now what the computer can do. We want to allow notebook contributors to see errors before they go to production.
Outcome:
You can now run notebooks in mobu as part of Github CI. Documentation here
Mobu’s role in phalanx#
Before: Mobu is an “add-on” phalanx service (it’s not required in the minimal deploy)
After: Mobu is a phalanx “core” service and participates in the bootstrap deploy
Discussion:
Up to now, mobu has been seen as an optional convenience service whose main function is to perform specific service tests, primarily for nublado and qserv. With the increased outside interest in phalanx as an internal developer platform, we are planning work to make the initial deployment easier. Mobu will play a role in performing self-checkout of these deployments; hence it will become a core phalanx service, like gafaelfawr.
Documentation#
Before: Documentation is primarily in technotes; service deployment docs are in phalanx.lsst.io
After: Create mobu.lsst.io documentation for developer (user) documentation.
Outcome:
Complete mobu documentation at mobu.lsst.io
Permissions#
Before: Creating new mobu flocks on the fly requires exec:admin permissions because it allows creating tokens for arbitrary bot users with arbitrary scopes.
This makes it hard for application developers to test new flocks or run ad hoc flocks (for load testing, for example).
After: Provide some mechanism for application developers to test their flocks without needing exec:admin permissions, and to pause flocks when performing maintenance on their applications.
Discussion:
Originally, the design of mobu assumed people would use the REST API to start and stop flocks. We then added autostart to make the running mobu flocks configuration-driven, and now that’s become the main way to use mobu. Ad hoc flocks are, however, still supported, and may be useful for application owers to test.
Currently, application developers won’t have any access to change the mobu configuration, since mobu is an infrastructure application. This means they’ll require help getting their flocks started, and iterating on a flock using the autostart configuration and restarting mobu (what SQuaRE normally does) is not available to them.
We need to rethink the interaction of the REST API and the Phalanx configuration for mobu, figure out where we want to put the relevant configuration, and probably figure out a better security model for manipulating running flocks. This probably includes additional operations on flocks as well, such as pausing a flock so that it still shows up in the daily report but reports as paused.